
What are Hashes and Why do we need them?

What is a hash function and a hash?
A hash function is simply a mathematical function that takes in input, and gives a unique output.
Here the input can be anything, as small as your name to as big as 10GB movie. When you put your name(input) into a hash function(eg. SHA-256) it will give you an output. This output will be same every time you put your name.
But if you change anything in the input, like adding a space in the name or making a letter capital, the output will change. Thus every unique input has a unique output.
Below is a diagram explaining what is a hash and a hash function, and how does this all work.
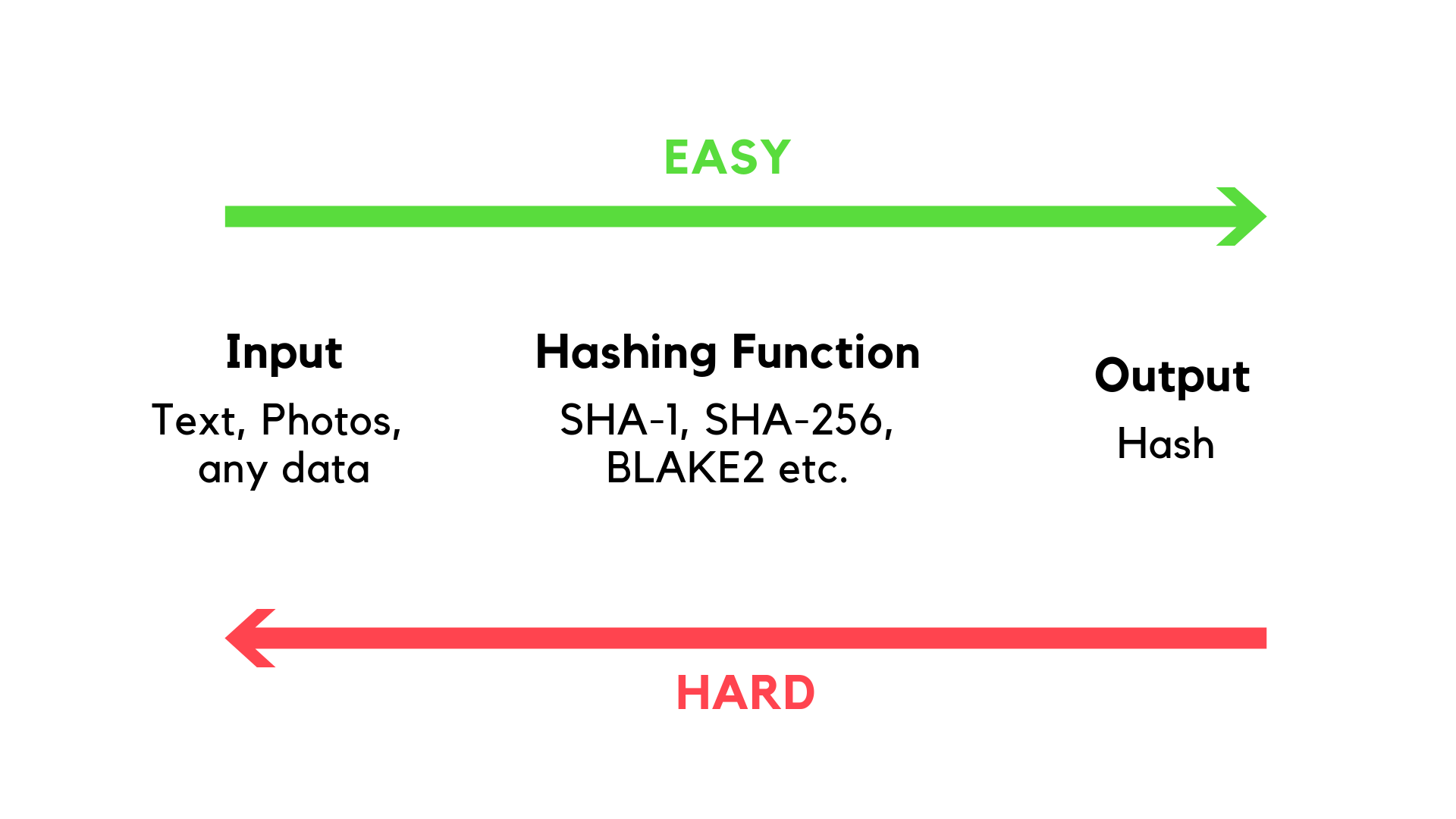
Note that it's easy to determine the output from an input(your name). But it's hard(nearly impossible) to get the input(your name) from the output.
The function which converts input to output is called a hash function, and the output is called a hash.
Here is an example of the SHA-256 hash function. Type your name in the input field and see what hash output you get.
Notice that even if you add a space or make a letter capital, the hash output changes.
There are also other hash functions such as SHA-1 (used by Git), SHA-256, or BLAKE2.
These hash functions differ by the internal mathematics or algorithms that they use to convert the input to the output. Due to the use of different algorithms, the output of these algorithms is different even for the same input.
You can check out the SHA-1 hash function below and see how SHA-1 returns a different type of output than SHA-256, for the same input.
Notice that the SHA-256 hash is longer than the SHA-1 hash. This is because SHA-1 creates a 160 bit(40 letters long) hash, while SHA-256 creates a 256 bit(64 letters long) hash.
Every good hash function generates hashes which satisfy the following important properties:
- deterministic : the same input message always returns exactly the same output hash. So, if you put your name again, you will get the same output hash.
- uncorrelated : a small change in the input message should generate a completely different hash.
- unique : it's infeasible to generate the same hash(output) from two different input messages
- one-way : it's infeasible to guess or calculate the input message from its hash. That's why we have a green arrow(showing easy) and a red arrow(showing hard) in the diagram.
But, Why Should I care about all this?
Hash functions are a core part of cybersecurity today, all over the world. They protect your passwords, money, and other confidential data…not just yours, but the data of big banks, hospitals, governments, everyone.
How do we protect our passwords using hash functions?
When you signup on a website, the website never stores your actual password. They store the hash(output) of the password(input).
So, when you log in and enter the password on the website, the website generates the hash of the password and checks if the hash of the entered password matches with the hash that we stored at the time of sign up.
To summerise, hashes help us in the following ways:
- The website owner cannot see your actual password.
- As the hash functions are one-way, thus even if someone hacks the website server and steals the hashes stored on the server, he can't figure out what the actual password was.
How IPFS uses Hashes?
Using the 4 features that we listed above, we can use a cryptographic hash to identify any piece of data: the hash is unique to the data we calculated it from and it’s not too long (a hash is a fixed length, so the SHA-256 hash of a 1 Gigabyte video file is still only 256 bits or 64 letters long), so sending it around the network doesn’t take up a lot of resources.
That’s critical for a distributed system like IPFS, where we want to be able to store and retrieve data from many places. A computer running IPFS can ask all the peers it’s connected to whether they have a file with a particular hash and, if one of them does, they send back the whole file. Without a short, unique identifier like a cryptographic hash, that wouldn’t be possible. This technique is called “content addressing” — because the content itself is used to form an address, rather than information about the computer and disk location it’s stored at.
Now as we have understood what is a hash and a hash function, let's move to content addressing and content identifiers(CIDs).