
Understanding IPFS in Depth(5/6): What is Libp2p?
In this part, we will study the networking Layer of IPFS and what it contributes to the awesomeness of IPFS. We will go through it’s working, specs and play around with it to understand it more clearly.

This post is a continuation(part 5) in a new “Understanding IPFS in Depth” series which will help anybody to understand the underlying concepts of IPFS. If you want an overview of what is IPFS and how it works, then you should check out the first part too 😊
 vasa
vasa
In part 4, we discussed the significance of Multiformats, How it Works and its technical specification of each multiformat protocol. We also went through a hands-on tutorial in which we played with the multiformats protocols. You can check it out here:
vasa
In our first part of the series we briefly discussed Libp2p. We saw that Libp2p “Moves data around” in IPFS(well, not just in IPFS). In this part, we will dive fully into Libp2p and discuss:
- The Significance of Libp2p: What is the philosophy behind it, Why do we need it and Where does it fit into IPFS?
- How does Libp2p Work?: An In-depth Explanation of all its modules.
- Playing with Libp2p: Well, It’s always fun to play 😊
I hope you learn a lot about IPFS from this series. Let’s start!
Why Libp2p? : The Significance of Libp2p
In order to understand its significance, we have to go back in history.
The early research on ARPANET(predecessor of the internet) began around the question that
How do you build a network which is so resilient, so that it could even survive a NUCLEAR WAR?
The reason that this topic was of such interest in the 1960s was that most of the communication infrastructure at that time looked like this:
These were banks of humans operators connecting wires to facilitate country-wide communication. This was a highly centralized system, which could be destroyed easily in a nuclear war.
Fast-forward to today’s world, most of the internet companies today have centralized servers, most of which are hosted in the data centers outside the cities. The internet we see today is still somehow full of services similar to the bank of human operators which are highly centralized and fragile(well, we aren’t in a constant threat of a nuclear war today, but any technical or natural disaster can cause great damage).
But Why do we need to rethink about networking in 2019?
Today, we are dependent on the internet more than ever. We are dependent on it for life and death situations. But the current internet, as we see it today is quite fragile and has several design problems. Most of these problems stem from the location-addressing.
Hmm, But What’s location addressing?
This means that whenever any device(your phone, laptop, fridge, car) connects to the internet(via wifi, broadband, satellite…whatever) it gets a name(and hence the data stored in it) based on its location.

The proposed solution to this is content addressing, which allows a much resilient, peer-to-peer model.
However, in order to give content addressing properties to the web, we have to go deeper into networking and overcome many of the challenges that the current internet infrastructure has. These challenges include things like:
- NATs: NATs blind devices from each other on the network. Ever tried to host a website from your college network? I bet the experience would have sucked.
- Firewalls: Apply to restrictive filters on the network, which restricts different devices to talk to each other. Every got facebook blocked on your office networks? Yeah, that’s firewalls right there.
- High-latency networks: This is why sometimes the internet is slow, and you are mad because your favorite movie on Netflix is buffering.
- Reliability: Networks which are just not reliable and keep failing. We all have a memory of one shitty wifi that would just lose connection every time.
- Roaming: Problems with changing IP addresses while roaming due to location-based addressing. We all use free wifi of the coffee shops that we visit. While using the wifi your device is assigned an IP address(the identity of your device). When you move out of the coffee shop, your IP changes(as you disconnect from the wifi). So, your device never has a single identity that stays the same over a period of time.
- Censorship: The fact that Google is banned in China and children(well, everybody) of Turkey have never used Wikipedia for their school assignments.
- Runtimes with different properties: Lots of devices with very different connectivity properties force developers to work very hard to get around their limitations to get connected with each other, and a lot of times they are just simply not able to connect at all.
Ever met a network engineer(IT guy) having a bad day? Well, pretty much every day. - Innovation is super slow: Innovation in networks land is really slowwww…It takes years or even a decade for a new protocol to go down the OSI stack and to be deployed on a large scale. Even with a huge amount of funding, it might take years to decades to deploy new fantastic ideas to the internet’s fabric.
- And the list goes on…
These problems are partly because of the location-addressing model. The proposed solution to these problems is content-addressing.
Libp2p is not the first project that is working on the peer-to-peer content-addressing model. There have been a ton of projects like eMule, Kazaa, LimeWire, Napster, BitTorrent, some of which even exist until today. There was a lot of research done on algorithms like Kademlia, Pastry which powered these projects. Even though all these projects existed and got popular, it is really hard to leverage the work done in the past. Most of these projects have the classic software usability problems.

These problems include:
- Lack of good documentation, or none at all.
- Restrictive Licensing or no licensing to be found.
- Old with last update more than a decade away.
- No easy to reach, point of contact.
- Closed Source(Product) or the source doesn’t exist anymore.
- No specification provided.
- The implementation doesn’t expose a friendly API.
- Projects that are tightly coupled with a specific use-case.
- Make a lot of assumptions about how they work.
And this is something that we still see today.
A good example of this is WebRTC, the peer-to-peer transport of the web platform. Most of its opensource implementations are build by hacking the Chrome browser and are buggy and unreliable.
So, there is a need for a future-proof framework, that can efficiently encapsulate all the standards, which would allow:
- faster innovation, as the things are modular as-well-as compatible.
- future-proof system; so that things do not break as we add new things in the coming future.
- cross compatible; not only this allows new things to be added but also keeps the support for previously used standards, so that we don’t kill the legacy systems.
Well, I know what you are thinking…

But, no. We are not talking about just another standard. Instead of creating just another project with another “unique” protocol, we are trying to build a toolkit that allows creating and managing these standards and protocol that do not suffer from the classic software usability problems.
Ok. Tell me What is this “Libp2p”?
The one-liner pitch is that libp2p is a modular system of protocols, specifications, and libraries that enable the development of peer-to-peer network applications.
Peer-to-peer basics
There’s a lot to unpack in that one-liner! Let’s start with the last bit, “peer-to-peer network applications.” You may be here because you’re knee-deep in the development of a peer-to-peer system and are looking for help. Likewise, you may be here because you’re just exploring the world of peer-to-peer networking for the first time. Either way, we ought to spend a minute defining our terms upfront, so we can have some shared vocabulary to build on.
A peer-to-peer network is one in which the participants (referred to as peers or nodes) communicate with one another directly, on more or less “equal footing”. This does not necessarily mean that all peers are identical; some may have different roles in the overall network. However, one of the defining characteristics of a peer-to-peer network is that they do not require a privileged set of “servers” which behave completely differently from their “clients”, as is the case in the predominant client/server model.
Because the definition of peer-to-peer networking is quite broad, many different kinds of systems have been built that all fall under the umbrella of “peer-to-peer”. The most culturally prominent examples are likely the file-sharing networks like BitTorrent, and, more recently, the proliferation of blockchain networks that communicate in a peer-to-peer fashion.
Before going further I would strongly recommend going through the core concepts of networking, which are explained beautifully here.
What problems can libp2p solve?
While peer-to-peer networks have many advantages over the client/server model, there are also challenges that are unique and require careful thought and practice to overcome. In the process of overcoming these challenges, while building IPFS, we(contributors of IPFS) took care to build the solutions in a modular, composable way, into what is now libp2p. Although libp2p grew out of IPFS, it does not require or depend on IPFS, and today many projects(including Libra aka ZuckBucks) use libp2p as their network transport layer. Together we can leverage our collective experience and solve these foundational problems in a way that benefits an entire ecosystem of developers and a world of users.
Here I’ll try to briefly outline the main problem areas that are addressed by libp2p today (early 2019). This is an ever-growing space, so don’t be surprised if things change over time.
Transport
At the foundation of libp2p is the transport layer, which is responsible for the actual transmission and receipt of data from one peer to another. There are many ways to send data across networks in use today, with more in development and still more yet to be designed. libp2p provides a simple interface that can be adapted to support existing and future protocols, allowing libp2p applications to operate in many different runtime and networking environments.
Identity
In a world with billions of networked devices, knowing who you’re talking to is key to secure and reliable communication. libp2p uses public key cryptography as the basis of peer identity, which serves two complementary purposes. First, it gives each peer a globally unique “name”, in the form of a PeerId. Second, the PeerId allows anyone to retrieve the public key for the identified peer, which enables secure communication between peers.
Security
It’s essential that we be able to send and receive data between peers securely, meaning that we can trust the identity of the peer we’re communicating with and that no third-party can read our conversation or alter it in-flight.
libp2p supports “upgrading” a connection provided by a transport into a securely encrypted channel. The process is flexible and can support multiple methods of encrypting communication. The current default is secio, with support for TLS 1.3 under development.
Peer Routing
When you want to send a message to another peer, you need two key pieces of information: their PeerId, and a way to locate them on the network to open a connection.
There are many cases where we only have the PeerId for the peer we want to contact, and we need a way to discover their network address. Peer routing is the process of discovering peer addresses by leveraging the knowledge of other peers.
In a peer routing system, a peer can either give us the address we need if they have it or else send our inquiry to another peer who’s more likely to have the answer. As we contact more and more peers, we not only increase our chances of finding the peer we’re looking for, we build a more complete view of the network in our own routing tables, which enables us to answer routing queries from others.
The current stable implementation of peer routing in libp2p uses a distributed hash table to iteratively route requests closer to the desired PeerId using the Kademlia routing algorithm.
Here is the best slide deck I ever encountered for understanding Kademlia.
Content Discovery
In some systems, we care less about who we’re speaking with than we do about what they can offer us. For example, we may want some specific piece of data, but we don’t care who we get it from since we’re able to verify its integrity.
libp2p provides a content routing interface for this purpose, with the primary stable implementation using the same Kademlia-based DHT as used in peer routing.
Messaging / PubSub
Sending messages to other peers is at the heart of most peer-to-peer systems, and pubsub (short for publish/subscribe) is a very useful pattern for sending a message to groups of interested receivers.
libp2p defines a pubsub interface for sending messages to all peers subscribed to a given “topic”. The interface currently has two stable implementations; floodsub uses a very simple but inefficient “network flooding” strategy, and gossipsub defines an extensible gossip protocol. There is also active development in progress on episub, an extended gossipsub that is optimized for single source multicast and scenarios with a few fixed sources broadcasting to a large number of clients in a topic.
An Infographic to sum it up
libp2p is the networking layer of IPFS
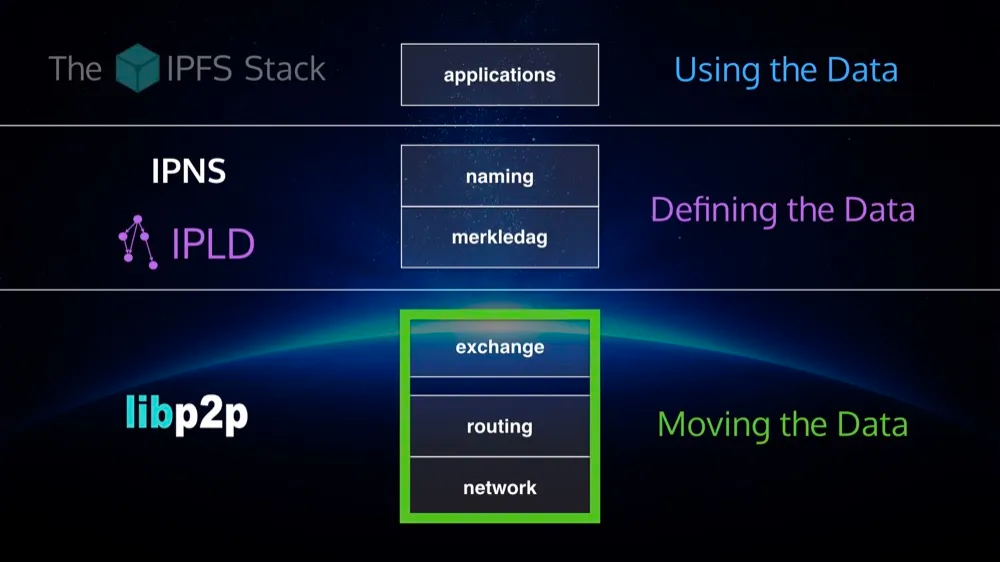
a collection of p2p protocols

modules that satisfy interfaces (roles)
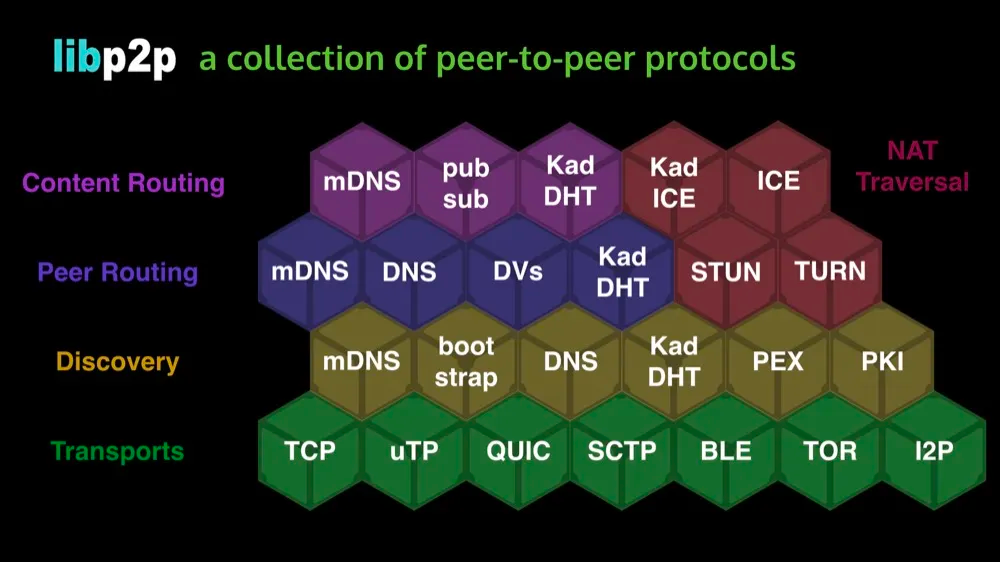
The whole of IPFS is made up of libp2p modules

An analogy to compare IPFS vs Libp2p

So, as we saw above, Libp2p is a collection of building blocks that expose a very well-defined, documented and tested interfaces so they are composable, swappable and hence upgradable.
In other words, Libp2p takes the current “vertical” OSI model and makes it horizontal.
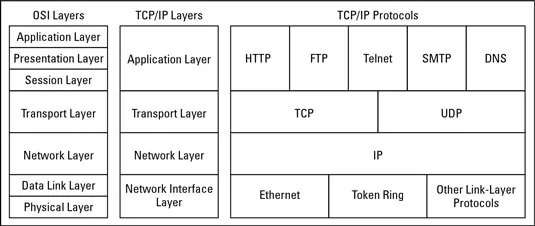
This current networking model has a few shortcomings:
- Repeated actions throughout multiple layers, hence a lot of duplicated work and wasting resources.
- Information is hidden between the layers, missing significant improvement opportunities.
This is mainly due to the fact that internet protocols are spread across multiple layers(as shown in the diagram) and are very tightly coupled which makes them hard to change, thus discouraging innovation.
Libp2p changes this and just gives you a frame in which all of these protocols can co-exist and cooperate.

If you are new to this idea(OSI model), I strongly recommend you to go through the following RFCs for much better understanding:
- RFC 1958: Architectural Principles of the Internet
- RFC 3439: Some Internet Architectural Guidelines and Philosophy
Implementations
Libp2p is available in the following official implementations:
- go-libp2p in Go
- js-libp2p in Javascript, for Node and the Browser
- rust-libp2p in Rust
- py-libp2p in Python
There are also a number of other community built implementations which you can use.
Well, now as we have talked about why we need to rethink about networking in 2019, what is libp2p and how libp2p is an improvement over the current networking model, it’s time for some action🚨🚨
Let play with Libp2p🔥🔥
In this tutorial, we are going to build a libp2p chat application including both Node.js and Browser clients.
The tutorial will give you the opportunity to build your application for one of three platforms/languages: Go, Node.js, and Web Browsers. See the preparation section below for your respective choice.
Installation steps
- Have your favorite code editor ready, if don’t have one, I recommend VSCode.
Preparing for Go track
- You need to have the Go language 1.12 compiler installed, please follow the instructions at https://golang.org/doc/install
- Bonus: learn basic concepts on the libp2p website and study the interfaces in go-libp2p-core.
Preparing for the JavaScript track
- Have git installed, https://git-scm.com/downloads.
- Node.js >= 10 installed + npm >= 6 installed.
- Download or clone the code at https://github.com/libp2p/js-libp2p-examples,
git clone https://github.com/libp2p/js-libp2p-examples.git.
Specific to Node.js
- Install dependencies by following the Setup directions at
 libp2p
libp2p
- Now open the folders sequentially and add do as directed in the todos.
Specific to Browsers
- Have the latest version of Firefox, Brave, or Chrome installed. Firefox was tested the most during the building of this workshop, so we’d recommend having that installed just in case there is an issue with your preferred browser.
- Install dependencies by following the Setup directions at
libp2p- Now open the folders sequentially and add do as directed in the todos.
Windows Users
If your npm config is not already set to support bash, you will need to do that for the Web Browser examples. Check out this Stack Overflow Answer for how to do that. This will enable Parcel to correctly locate the appropriate, nested files.
If you have any doubts/questions/suggestions, then shoot them in the comments. For more details on the tutorial, you can visit IPFS camp repo, where you can learn a ton about IPFS.
ipfsI recently attended the IPFS Camp in June 2019 and it was an amazing experience.

Congratulations🎉🎉 You now have the power to build Future-proof networks.
That’s it for this part. In the next part, we will explore Filecoin. You can check it out here:
vasa